Incident Response Bottlenecks: Where Your MTTR Is Actually Lost
Learn how OpsBrief helps teams reduce MTTR by connecting incidents, deployments, alerts, and operational events into one searchable operational timeline
Alexander Eric

Reducing MTTR (Mean Time to Resolution) is a priority for most engineering and operations teams. But when incidents happen, the biggest delays often don’t come from fixing the issue itself. They come from everything surrounding the investigation process: fragmented alerts, unclear ownership, missing context, and scattered operational data. In many environments, teams lose valuable time simply trying to understand what changed, who needs to respond, and whether related systems are also affected. That’s where many incident response bottlenecks actually begin.
MTTR Problems Usually Start Before Resolution
When teams review incidents after the fact, they often focus on the technical root cause. But operational delays frequently happen much earlier in the response cycle. Common examples include:
- Waiting for the right team to acknowledge an alert.
- Searching through Slack threads for deployment context
- Manually correlating logs, incidents, and infrastructure changes
- Escalating issues across disconnected tools
- Trying to determine whether an issue is isolated or systemic
Even relatively small delays can compound during active incidents. A five-minute delay in identifying a deployment issue can quickly turn into thirty minutes of uncertainty across engineering, product, and operations teams.
Fragmented Operational Visibility Slows Response
Modern teams rely on dozens of tools to manage infrastructure and services. Alerts may come from Datadog, deployments from GitHub, incident escalations from PagerDuty, and discussions from Slack or Microsoft Teams. The problem is that operational context becomes fragmented across systems. Without a centralized operational timeline, responders are forced to piece together events manually while the incident is still unfolding. This increases:
- Detection latency
- Escalation delays
- Duplicate investigations
- Communication overhead
- Overall incident resolution time

Context Switching Creates Hidden Delays
One of the biggest contributors to slow incident response is constant context switching. Engineers jump between dashboards, alerts, chats, deployment logs, and monitoring systems, trying to reconstruct a timeline of events. This creates cognitive overhead during already high-pressure situations. Instead of focusing on diagnosis and remediation, responders spend time gathering information from scattered systems. Operational intelligence becomes difficult when teams lack a unified view of what changed across the environment.
Why Event Correlation Matters
Many incidents are connected to recent operational changes. A deployment, configuration update, infrastructure modification, or third-party dependency issue may all contribute to service degradation. The challenge is identifying those relationships quickly. Teams that can correlate operational events in real time typically reduce investigation time significantly because responders immediately gain context around:
- Recent deployments
- Infrastructure changes
- Service dependencies
- Affected systems
- Ongoing incidents
This helps eliminate guesswork during incident triage.
Building Faster Operational Awareness
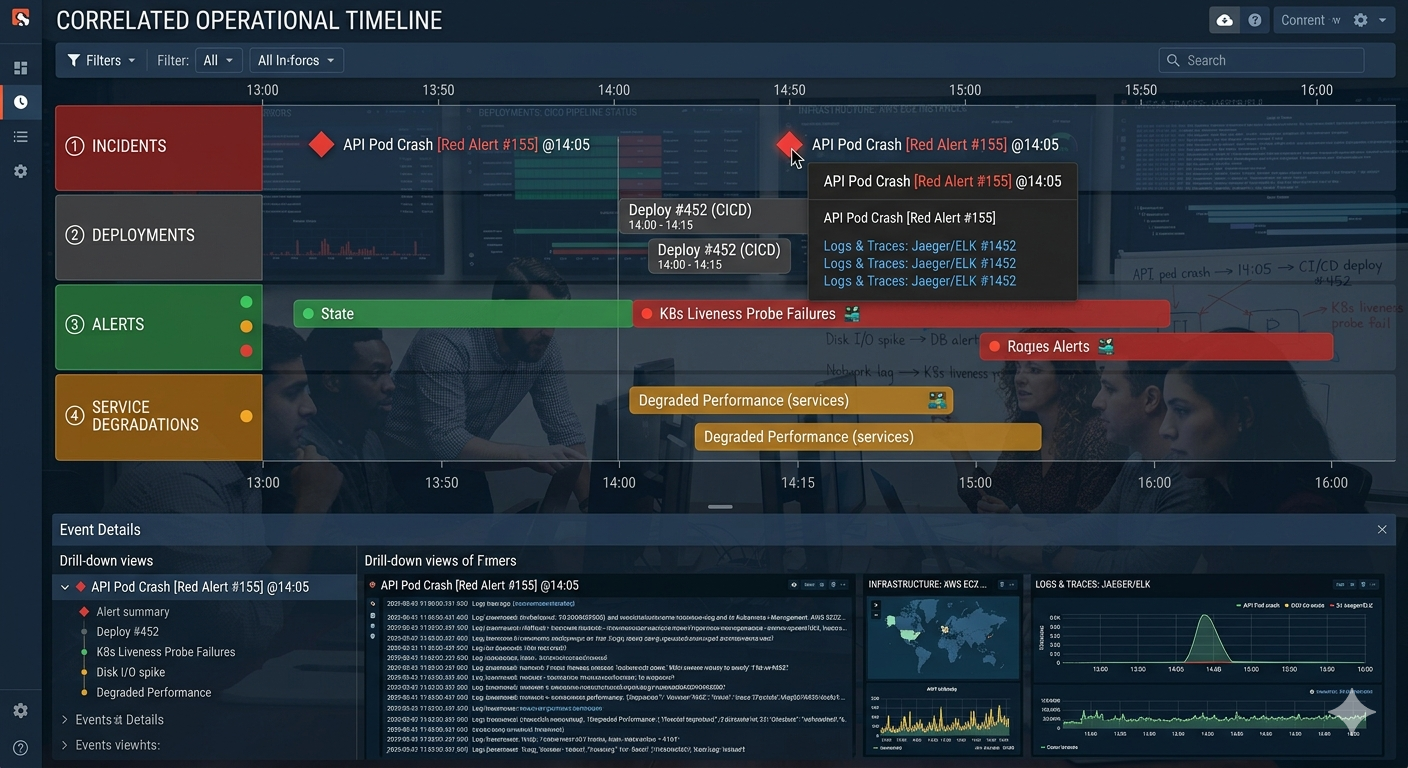 Improving MTTR often depends less on adding more alerts and more on improving operational awareness.
OpsBrief helps teams organize operational activity from tools like Slack, GitHub, PagerDuty, Datadog, and Microsoft Teams into a centralized operational timeline.
Instead of manually searching for context during incidents, teams can quickly understand:
Improving MTTR often depends less on adding more alerts and more on improving operational awareness.
OpsBrief helps teams organize operational activity from tools like Slack, GitHub, PagerDuty, Datadog, and Microsoft Teams into a centralized operational timeline.
Instead of manually searching for context during incidents, teams can quickly understand:
- What changed?
- When it changed
- Which systems were affected?
- Who was involved?
- Whether related incidents are occurring simultaneously
This creates faster alignment across engineering, operations, and product teams during active response efforts.
Conclusion
Most MTTR delays don’t happen during the final fix. They happen during the confusion that surrounds detection, investigation, escalation, and coordination. Teams that improve operational visibility and event correlation can reduce response bottlenecks long before resolution begins.


